
Category: Relational Databases
-
Impact of Scaling in VantageCloud Lake
Post that presents two cheat sheets summarising the impact of scaling in VantageCloud Lake for the Compute and the Primary Clusters.
-
Compute Clusters in VantageCloud Lake
This post explains the Compute Clusters’ main characteristics, how to use them for cost management, plan for scaling, and mapping applications with Compute Groups.
-
VantageCloud Lake on GCP: Network configuration
Cheat sheet with the key network elements you need to connect with your Teradata VantageCloud Lake on Google Cloud and a detailed explanation.
-
VantageCloud Lake on Azure: Network configuration
Cheat sheet with the key network elements you need to connect with your Teradata VantageCloud Lake on Azure and a detailed explanation.
-
VantageCloud Lake on AWS: Network configuration
Cheat sheet with the key network elements you need to connect with your Teradata VantageCloud Lake on AWS and a detailed explanation.
-
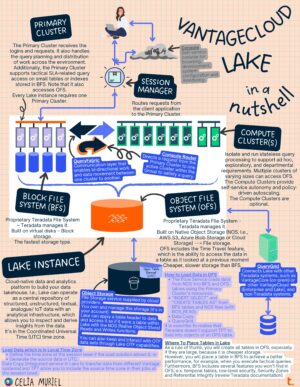
VantageCloud Lake in a Nutshell
Post that includes an infographic summarising the critical VantageCloud Lake elements and the basis for using them for a quick start.