
VantageCloud Lake is Teradata’s cloud-native data and analytics platform. Namely, Teradata designed VantageCloud Lake architecture to be a good fit for data lakehouses and to leverage the cloud capabilities better while keeping Teradata’s ClearScape Analytics.
This post explains VantageCloud Lake architecture and its main capabilities.
For a quick summary of the critical VantageCloud Lake elements and the basis for using them, check the post VantageCloud Lake in a Nutshell and the infographic in it.
What is Lake?
VantageCloud Lake is a cloud-native data and analytics platform that makes an excellent fit to build your data lakehouse. In other words, VantageCloud Lake can operate as a central repository of structured, unstructured, textual, analogue/ IoT data with an analytical infrastructure, which allows us to inspect and derive insights from the data in the lakehouse.
The Data Lakehouse
The analytical architectures have evolved from the Data Warehouse and Data Mart to the Data Lake, and now, the Data Lakehouse.

Roughly speaking:
- The data warehouse is relational data for business reporting.
- The data lake is for data science and machine learning, using data of any structure or file format.
- The data lakehouse is a single data architecture that combines and unifies the architectures and capabilities of data lakes and data warehouses. Specifically, it enables greater agility for all sorts of analytics but with fewer data redundancies, a simpler architecture, and a more consistent view of the semantics.
According to Gartner, the data warehouse and data lake converge into the data lakehouse.
However, Forrester believes that the data lakehouse will replace separate data warehouses and data lakes.
To learn how to architect data lakehouses, read Bill Inmon and Ranjeet Srivastava’s book Building the Data Lakehouse. Incidentally, Bill Inmon is the father of the Data Warehouse.
What Lake is for
Teradata offers data and analytics solutions in the three leading Service Cloud Providers: AWS, Azure and Google Cloud Platform. The umbrella term for this offering is VantageCloud.
- VantageCloud Enterprise is meant to optimise performance, and it uses the traditional Teradata architecture.
- VantageCloud Lake is built to optimise cost storage, leverage cloud capabilities and speed up the response to your critical queries.
ClearScape Analytics
In like manner, Enterprise and Lake offer the complete set of Teradata analytic functions for Machine Learning, Data Science, and traditional reporting in a bundle called ClearScape Analytics.

Particularly, ClearScape Analytics comprises in-database functions, open and connected integrations/APIs, and features enabling full-scale activation and operationalisation of analytics.

Open Table Formats
Lake is optimised to use Object Storage (AWS S3, Azure Blob Storage, and Cloud Storage), and thus, it integrates with Open Table Formats.
The Open Table Format (OTF) is a file format for storing tabular data that is easily accessible and interoperable across various data processing and analytics tools. There are several Open Table Formats, such as Deta Lake, Apache Iceberg, and Apache Hudi.

Parenthetically, Open Table Formats sit atop the object store, providing low-cost storage for your organisation.
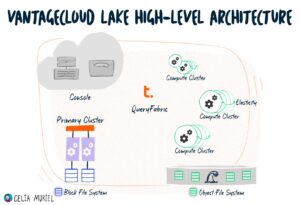
Lake’s Architecture

First, Lake allows you to store analytic source data and user tables in Teradata Shared Storage (TSS) using public cloud storage options, i.e. AWS S3, Azure Blob Storage and Cloud Storage.
Specifically, TSS is divided into:
- Managed Storage for internally owned Teradata tables. A new optimised Object File System manages it.
- Customer-owned storage for externally owned data, that’s to say, your buckets in AWS S3, Azure Blob Storage or Cloud Storage. This storage is accessible outside the tenant via NOS (Native Object Storage) API connectivity. Open Table Formats (OTF) resides in the Customer-Owned Storage tier.

To clarify, the Customer-Owned Data (data in your buckets) is not replicated and persisted within Lake’s platform.
Ecosystem Connectivity
The Primary Cluster has disks attached to the traditional Teradata Block File System (BFS). Additionally, it can read and write from the Object File Storage (OFS, Teradata-Managed Storage) and Native Object Storage (NOS, Customer-Managed Storage).
As for the Compute Clusters, they can only read and write from OFS and NOS.

To move data to/ from Lake into other Teradata and non-Teradata databases, you can use QueryGrid.
The Three Storage Types
The table below summarises the three storage types we consider in Lake:

Block File System (BFS)
Proprietary Teradata File System – Teradata manages it.
Built on virtual disks – Block storage.
The fastest storage type.
It supports temporal and all indexes.
Requires backup.
You place data here when you require specific features or the performance dictates it.
Do not locate data here first.

Object File Storage (OFS)
Proprietary Teradata File System – Teradata manages it.
Built on Native Object Storage (NOS) – File storage -. I.e., AWS S3, Azure Blob Storage or Cloud Storage.
Cheaper, slower storage than BFS.
No indexes or temporal.
It supports Time Travel (data protection feature).
Three copies by nature.
You should place data here as a default.
Only move data out of OFS when speed or features require it.

Native Object Storage (NOS)
Raw Native Object Storage. I.e., as provided by the cloud providers. – File Storage.
Customers own this storage (it’s in their accounts).
Teradata doesn’t manage it.
Lake can apply a table header to data and access it as if it were a table within Lake.
Some latency depending on the file type.
Locate data here when there is a business or tactical reason to have it persist outside of Lake.
Transparent for end-user applications – it works with SQL functions, Python and R.
OFS vs NOS
Let’s explain the differences between OFS (Teradata-Managed Storage) and NOS (Customer-Managed Storage).
Native Object Storage (NOS) is an umbrella term to refer to the object storage services each Cloud Service Provider (CSP) offers.
- AWS S3, Azure Blob Storage or Cloud Storage.
- The Lake Engine reads and writes files in NOS with the NOS_READ and NOS_WRITE functions.
vs
Teradata OFS is a proprietary file system built on NOS.
- It’s optimised for performance, including caching, optimised spool, and indexed metadata.
- So we can’t just upload files to NOS and expect the Lake Engine reads them as an OFS table.
- We must upload data to OFS tables through the Lake Engine ➦ The Engine transforms the data to the appropriate format.
Regarding compute processing, Lake splits it into operational clusters.

In the first place, a cluster is a set of BYNET-connected nodes.
- The Primary Cluster receives the logins and requests. It also handles the query planning and distribution of work across the environment. Additionally, the Primary Cluster manages the high-performance Block Disk Storage for select operational workloads.
- The Compute Clusters aim to isolate and run stateless query processing to support ad hoc, exploratory, and departmental requirements. Multiple clusters of varying sizes can access a single shared cloud-native data store. The Compute Clusters provide self-service autonomy and policy-driven autoscaling.
Let’s analyse the clusters and Object Storage in more detail.
Primary Cluster
Lake requires one Primary Cluster.

The Primary Cluster is similar to an Enterprise system.
Furthermore, you can scale it up/down and in/out the Primary Cluster using Blue-Green upgrade processes without user workload disruptions.
Namely, Teradata designed the Primary Cluster to store user data supporting tactical SLA-related query access (small tables or indexes).
Incidentally, a Primary Cluster must have at least two Primary Compute instances for redundancy.
A vital task of the Primary Cluster is to optimise queries – It determines which type of cluster (Primary and/ or Compute Clusters) will execute which part of a query.
Notably, the Primary Cluster Optimizer Includes a Global Planner.

For your attention, the Optimizer only engages the Global Planner if the query can use the Compute Clusters.
So, the Global Planner decides on:
- If the Primary Cluster must access the Primary Cluster tables.
- If the Compute Clusters must access the Object Storage.
- For other steps, such as joins and aggregations, the Global Planer makes cost-based decisions.
Compute Clusters
The Compute Clusters represent a decentralized unit of autoscaling. Note that they are optional.

So when you deploy Compute Clusters, Lake routes compute-intensive query steps to them.
As previously explained, the Compute Clusters depend on the Primary Cluster Optimizer to direct the steps the Compute Cluster will execute for a query.
In contrast with the Primary Cluster, the Compute Clusters do not contain storage for user tables. However, they support spool files.
In February 2024, when you create a Compute Cluster, you can choose between two types:
- Standard Compute Cluster, and
- Analytics Compute Cluster, which is fine tuned for analytic workloads. The nodes in an Analytics Compute Cluster have less number of AMPs and more memory and CPU per AMP.
In due time, Teradata will offer enhancements to the Compute Cluster types by adding new features to the existing types or creating new Compute Cluster types. Sometimes, they refer to these improvements as “Specialty Compute Clusters”. Their goal is to provide appropriate Compute Cluster types that better isolate different workloads, either if you decide to break down your workload by department (Marketing, Financial, Shipping, etc.) or by process type (ETL, reporting, etc.).
Compute Groups and Compute Profiles
On a different note, multiple Compute Clusters instances are grouped into a Compute Group. Departments or applications own their own Compute Groups, so the Compute Groups isolate work from different departments or applications. Additionally, the Compute Groups allow for control of the budget at the departmental level.
Furthermore, you assign users to a default Compute Group.
Also, the Compute Groups automatically scale clusters as demand within every Compute Group grows or diminishes.
Not to mention that the Compute Groups are composed of one or more Compute Profiles. The Compute Profile:
- Defines the number of initial Compute Clusters and the upper limit on auto-scale.
- Specifies the cluster instance T-shirt size.
- You can assign a time window to it.
- Multiple Compute Profiles allow different Compute Cluster definitions by time of day.
- When a new Compute Profile becomes active, new Compute Clusters will be provisioned, and the previous Compute Clusters will be discarded.

The Instance T-shirt size
As for the instance T-shirt size, it describes the number of nodes within each Compute Cluster in the Compute Group. Teradata calls T-shirt sizes the instance size to differentiate it from the virtual machine sizes the Cloud Service Providers use to describe the resources assigned to every virtual machine type.
In the previous diagram, each Compute Cluster has a Large T-shirt size, i.e. eight nodes, in the Day Compute Profile. In the Night Compute Profile, each Compute Cluster has a Medium T-shirt size, i.e. four nodes.
So, the Compute Cluster T-shirt sizes are:
| Instance Size (T-Shirt Size) | Node Count | Power Increase |
| XSmall | 1 | Dev |
| Small | 2 | Base |
| Medium | 4 | 2X |
| Large | 8 | 4X |
| 1x_Large | 16 | 8X |
| 2x_Large | 32 | 16X |
| 3x_Large | 64 | 32X |
Correspondingly, each Compute Cluster comes with a map name that starts with the string “TD_COMPUTE” and reflects the T-shirt size. For example, TD_COMPUTE_MEDIUM is used for the Medium T-shirt size (4 nodes).
Moreover, you can modify a Compute Profile on a live system without interrupting the user queries:
- You can change the T-shirt size.
- You can change the scaling policy.
- You can change the start/stop policy.
Assigning Users to Compute Groups
Incidentally, the new field in User/Profile records holds a Compute Group name, specified by “COMPUTE GROUP =”.
-- Create the Compute Group
CREATE COMPUTE GROUP MktgGrp
-- Update the Department's Users or Profiles
MODIFY PROFILE MktgDeptProf
COMPUTE GROUP = MktgGrpYou update the user and/ or the profile records within a department to add a Compute Group name. So, moving forward, all the user’s queries will be eligible to use clusters in the specified Compute Group.
However, if a user or a profile does not contain a Compute Group name, their queries will run on the Primary Cluster.
Thus, assigning users to Compute Groups allows control over who can access Department resources.
In addition, the SET SESSION statement allows the user to specify a different Compute Group.
Connecting the Primary and Compute Clusters
As for the connection between the Primary and the Compute Clusters, Lake uses the Compute Router.

Specifically, the Compute Router directs a request from the Primary Cluster to one active Cluster within the Group to satisfy a query. The AMPs within the selected Compute Cluster will work to fulfil the request.
Of course, each Compute Cluster is isolated from every other Cluster. Thus, multiple Compute Clusters within the group can work on different queries simultaneously.
Finally, the QueryFabric is a communication layer that enables bi-directional work and data movement between one cluster to another within a Lake instance.
Access to OFS
OFS uses different performance techniques to support efficient access. The most important consideration is that Lake creates one internal index structure, shaped like a tree, for each OFS table. The index has a single root and multiple leaf nodes.
The OFS index carries the minimum and maximum values in the root (for each leaf). Lake calculates these values with statistics collected automatically for up to 64 columns per table and the leaf objects (for each data object). Mind you, the index row sizes can be up to 1 MB.
In the case of the columnar format (the default in Lake’s tables), each Data Object contains one Row Group broken into Pages within Column Chunks.


Lake dynamically hashes these internal indexes, which provides efficiency in multiple ways:
- Filtering out selected rows.
- Pre-positioning index entries across AMPs.
- Join column redistribution.
On another front, if you want to run tactical queries on data you store in OFS, you can create a Single-Table Join Index on the Primary Cluster for a large table you store in OFS.
In that Single-Table Join Index (STJI), you should include the columns the tactical query needs. So, the optimiser will choose to use the join index.
Today, if an OFS table has an STJI, all data maintenance for the OFS table occurs on the Primary Cluster.

Consequently, a Join Index on the Primary Cluster allows skipping access to the Object File System. It provides quicker, more consistent tactical query performance.
Wrap-Up
In this post, I have discussed VantageCloud Lake architecture. You should also read the posts:
- Considerations To Load Data Into VantageCloud Lake,
- VantageCloud Lake: Autoscaling the Compute Clusters,
- Time Travel in VantageCloud Lake,
- Session Manager in Lake: The Key to High Availability (which explains the Blue-Green upgrade, among other things),
- The Path of a Query in VantageCloud Lake,
- VantageCloud Lake in a Nutshell,
- VantageCloud Lake on AWS: Network configuration,
- VantageCloud Lake on Azure: Network configuration,
- VantageCloud Lake on GCP: Network configuration,
- Compute Clusters in VantageCloud Lake,
- Impact of Scaling in VantageCloud Lake, and
- Open Table Format in VantageCloud Lake.
Additionally, you can use Teradata’s resources to learn more about Lake:
- Lake online documentation.
- The following Orange Books (remember that Teradata only makes orange books available to customers):
- Videos about Lake on Teradata’s YouTube channel, such as:
- You can Bring Your Own Viewpoint to VantageCloud Lake.
- The Teradata Developer Portal offers plenty of resources, including:
- Forums in Teradata Community,
- Publicly available downloads from Teradata,
- Technical blog posts on Medium,
- Teradata’s Github account, and
- More assets
I updated this post on 10 November 2023 to include a link to the post Considerations To Load Data Into VantageCloud Lake.
I added a link to the post VantageCloud Lake: Autoscaling the Compute Clusters on 16 November 2023.
This post was updated on 23 November 2023 to add a link to the post Time Travel in VantageCloud Lake.
I updated this post again on 30 November 2023 to include a link to the post Session Manager in Lake: The Key to High Availability.
I included a link to the post The Path of a Query in VantageCloud Lake on 5 December 2023.
This post was again updated with the link to the post VantageCloud Lake in a Nutshell on 9 December 2023.
On 24 December 2024, I included the Compute Cluster types in this post.
This article was amended on 16 April 2024 to add the links to the posts about network configuration for VantageCloud Lake on AWS and Azure.
I updated this article on 25 July 2024 to add the link to the post about network configuration for VantageCloud Lake on GCP.
On 29 July 2024, I added the link to the post Compute Clusters in VantageCloud Lake.
I modified this post on 30 July 2024 to include links to the posts Impact of Scaling in VantageCloud Lake and Open Table Format in VantageCloud Lake.
Leave a Reply