
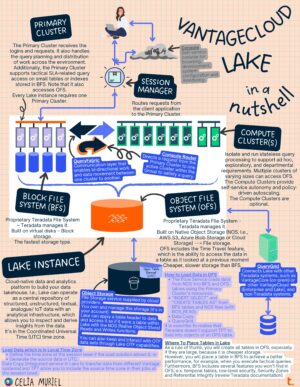
I have extensively talked about different aspects of VantageCloud Lake in previous posts.
In this post, I summarise the key aspects of VantageCloud Lake if you want to start quickly. You can learn other features as you need them.
What You Need to Know about Lake
The infographic that opens this post summarises the critical Lake elements and the basis for using them. You can find a high-resolution VantageCloud Lake in a Nutshell image in a repository in my GitHub account.
Main Lake components
In summary, the main Lake components are:
- Lake instance: Cloud-native data and analytics platform to build your data lakehouse. I.e., Lake can operate as a central repository of structured, unstructured, textual, analogue/ IoT data with an analytical infrastructure, which allows you to inspect and derive insights from the data. It’s in the Coordinated Universal Time (UTC) time zone.
- Console: Self-service console for browsing, development, system configuration and monitoring.
- Session Manager routes requests from the client application to the Primary Cluster.
- The Primary Cluster receives the logins and requests. The Primary Cluster also handles the query planning and distribution of work across the environment. Additionally, it supports tactical SLA-related query access on small tables or indexes stored in the Block File System (BFS). Note that it also accesses the Object File System (OFS). Every Lake instance requires one Primary Cluster.
- The Compute Clusters isolate and run stateless query processing to support ad hoc, exploratory, and departmental requirements. Multiple clusters of varying sizes can access the Object File System (OFS). The Compute Clusters provide self-service autonomy and policy-driven autoscaling. They are optional.
- Block File System (BFS): Proprietary Teradata File System (Teradata manages it). It is built on virtual disks (block storage). BFS is the fastest storage type.
- The Object File System (OFS) is also a proprietary Teradata File System. However, OFS is built on Native Object Storage (NOS). Therefore, it is a file storage. OFS includes the Time Travel feature, which is the ability to access the data in a table as it looked at a previous moment. OFS is a cheaper, slower storage than BFS.
- QueryFabric: Communication layer that enables bi-directional work and data movement between one cluster to another.
- The Compute Router directs a request from the Primary Cluster to one active Cluster within the Group to satisfy a query.
Other Solutions in the Ecosystem
Additionally, you should know that the above components have a tight relationship with:
- Object Storage: File Storage service supplied by cloud providers. You own and manage this storage (it’s in your account). Lake can apply a table header to data and access it as if it were a table within Lake with the NOS (Native Object Store) Reads and Writes functions.
- You can also keep and interact with OTF data sets through Lake OTF capabilities.
- QueryGrid: Teradata solution that connects Lake with other Teradata systems, such as VantageCore (on-prem) or other VantageCloud (Enterprise and Lake), and non-Teradata systems.
Load Data in Lake
Equally important to know the Lake architecture at a high level is how to load data and where to place it.
First of all, if you need to load data in a local time zone, you must define the time zone at the session level if the load solution allows it, or generate the source data in UTC. Data Copy (integrated service in Lake to transfer data from different Vantage systems) and TPT allow you to include the source time zone in their jobs at the session level.
Regarding where to place the data, you should know that as a rule of thumb, you will create all tables in OFS, especially if they are large because it is cheaper storage. However, you will place a table in BFS to achieve a better performance, for example, when you execute tactical queries. Furthermore, BFS includes several features you won’t find in OFS, e.x. temporal tables, row-level security, Security Zones and Referential Integrity (review Teradata documentation).
The Primary Cluster is similar to a VantageCloud Enterprise system, so you’ll load data as you do it.
Nevertheless, if you want to load data directly in OFS, you can use any of the following solutions:
- “INSERT SELECT” and “CREATE TABLES AS” from BFS tables and NOS files (with NOS_READ).
- Data Copy.
- QueryGrid.
It is important to realise that Teradata doesn’t support TPT to load into objects of an OFS table.
In-Depth Lake Posts
As I mentioned at the beginning, I’ve written posts that cover different aspects of Lake in detail. If you want to know more, check them:
- VantageCloud Lake Architecture.
- Considerations To Load Data Into VantageCloud Lake.
- VantageCloud Lake: Autoscaling the Compute Clusters.
- Time Travel in VantageCloud Lake.
- Session Manager in Lake: The Key to High Availability.
- The Path of a Query in VantageCloud Lake.
- VantageCloud Lake on AWS: Network configuration.
- VantageCloud Lake on Azure: Network configuration.
- VantageCloud Lake on GCP: Network configuration.
- Compute Clusters in VantageCloud Lake.
- Impact of Scaling in VantageCloud Lake.
- Open Table Format in VantageCloud Lake.
This article was amended on 16 April 2024 to add the links to the posts about network configuration for VantageCloud Lake on AWS and Azure.
I updated this article on 25 July 2024 to add the link to the post about network configuration for VantageCloud Lake on GCP.
On 29 July 2024, I added the link to the post Compute Clusters in VantageCloud Lake.
I modified this post on 30 July 2024 to include links to the posts Impact of Scaling in VantageCloud Lake and Open Table Format in VantageCloud Lake.
Leave a Reply