
Category: Relational Databases
-
The Path of a Query in VantageCloud Lake
This post explains the path a query takes to move through VantageCloud Lake and what steps execute on every cluster.
-
Session Manager in Lake: The Key to High Availability
The Session Manager routes requests from the client application to the Primary Cluster in VantageCloud Lake. Teradata designed the Session Manager to provide users with an additional high-availability layer. The reason is that the Session Manager minimises the impact of planned and unplanned outages on the workload running on the Lake instances. This post explains…
-
Time Travel in VantageCloud Lake
VantageCloud Lake supports the Time Travel feature, i.e. the ability to access the data in a table as it looked at a previous moment. This post explains how.
-
VantageCloud Lake: Autoscaling the Compute Clusters
This post explains how the autoscale mechanism works for the VantageCloud Lake Compute Clusters and what triggers it.
-

Considerations To Load Data Into VantageCloud Lake
Teradata VantageCloud Lake architecture uses two file systems: Block File System (BFS) and Object File System (OFS). While OFS is cost-effective, BFS enables faster operations and features not available in OFS, such as temporal tables and row-level security. Additionally, the Lake instances are in the UTC zone, which conditions how to load data. This post…
-
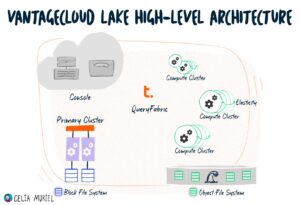
VantageCloud Lake Architecture
VantageCloud Lake is Teradata’s cloud-native data and analytics platform. This post explains Lake’s architecture, including OFS and BFS storage, and its main capabilities.